

DETECT & REMOVE OUTLIERS IN REGRESSION
- Ahmed R. Alsaber
- Jul 27, 2017
- 3 min read
A observation that is substantially different from all other ones can make a large difference in the results of regression analysis. Outliers occur very frequently in real data, and they often go unnoticed because nowadays much data is processed by computers, without careful inspection or screening. Outliers may be a result of keypunch errors, misplaced decimal points, recording or transmission errors, exceptional phenomena such as earthquakes or strikes, or members of a different population slipping into the sample.
Outliers and leverage
Outliers play important role in regression. It is common practice to distinguish between two types of outliers. Outliers in the response variable represent model failure. Such observations are called outliers. Outliers with respect to the predictors are called leverage points. They can affect the regression model, too. Their response variables need not be outliers.
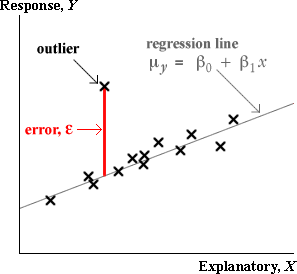
A bad leverage point is a point situated far from the regression line around which the bulk of the points are centered. Said another way, a bad leverage point is a regression outlier that has an X value that is an outlier among X values as well (it is relatively far removed from the regression line). Bad leverage point has grossly effect estimate of the slope of the regression line if an estimator with a small breakdown point is used. Bad leverage points reduce the precision of the regression coefficients.
Detecting Influential Observations
Many numerical and graphic diagnostics for detecting outliers and influential cases on the fit have been suggested.
Numerical diagnostics
Diagnostics are certain quantities computed from the data with the purpose of pinpointing influential points, after which these outliers can be removed or corrected. When there are only one a single outlier, some of these methods work quite well by looking at the effect of deleting one point at a time.
Influence: An influential observation is one which is an outlier with leverage and affects the intercept and slope of a model significantly. (Using SPSS)

Carry out simple linear regression through Analyze Regression Linear with Dependent variable and Independent(s).
In the Save menu, select Standardised residuals, Cook’s and Leverage values. The values for each individual will be added to the data set.
Cooks distance: This is calculated for each individual and is the difference between the predicted values from regression with and without an individual observation. A large Cook’s Distance indicates an influential observation. Compare the Cooks value for each observation with 4/n where n is the number of observations. Values above this indicate observations which could be a problem.
Standardized Residuals are the residuals divided by the estimates of their standard errors. They have mean 0 and standard deviation 1. There are two common ways to calculate the standardized residual for the i-th observation. Studentized residuals are a type of standardized residuals that can be used to identify outliers. One uses the residual mean square error from the model fitted to the full dataset (internally studentized residuals). The other uses the residual mean square error from the model fitted to the all of the data except the i-th observation (externally studentized residuals). The externally standardized residuals follow at t distribution with n-p-2 df.
The studentized residuals are a first means for identifying outliesrs. Attention should be paid to studentized residuals that exceed +2 or -2 and get even more concerned about residuals that exceed |2| and
even yet more concerned about residuals that exceed |3| .
Why we do this approach during our regression analysis:
1- To improve the level of R-Square.
2- To adjust the p-value of your predictors.
3- To make your regression model to be more reliable and measurable.
References:
Blatná, D.: Robust Regression. In: Applications of mathematics and statistics in economy. Wroclav 2005 (in print).
Dallal, G. E.: Regression Diagnostics. http://www.tufts.edu/gdallal/
Hampel,F.R.- Ronchetti,E.M.- Rousseeuw, P.J.- Stahel, W.A.: Robust Statistics. The Approach Based
on Influence Functions. J.Wiley, N.York 1986. ISBN 0-471-82921-8.
Rousseeuw, P.J.- Leroy,A.M.: Robust Regression and Outlier Detection. J.Wiley, New Jersey 2003.
ISBN 0-471-48855-0.